Reactive Programming 一种技术,各自表述
前言
作为一名 Java 开发人员,尤其是 Java 服务端工程师,对于 Reactive Programming 的概念似乎相对陌生。随着 Java 9 以及 Spring Framework 5 的相继发布,Reactive 技术逐渐开始被广大从业人员所注意,笔者作为其中一员,更渴望如何理解 Reactive Programming,以及它所带来的哪些显著的编程变化,更为重要的是,怎么将其用于实际生产环境,解决当前面临的问题。然而,随着时间的推移和了解的深入,笔者对 Reactive Programming 的热情逐渐被浇息,对它的未来保持谨慎乐观的态度。
本文从理解 Reactive Programming 的角度出发,尽可能地保持理性和中立的态度,讨论 Reactive Programming 的实质。
初识 Reactive
笔者第一次接触 Reactive 技术的时间还要回溯到 2015年末,当时部分应用正使用 Hystrix 实现服务熔断,而 Hystrix 底层依赖是 RxJava 1.x,RxJava 是 Reactive 在 Java 编程语言的扩展框架。当时接触 Reactive 只能算上一种间接的接触,根据 Hystrix 特性来理解 Reactive 技术,感觉上,Hystrix 超时和信号量等特性与 Java 并发框架(J.U.C)的关系密切,进而认为 Reactive 是 J.U.C 的扩展。随后,笔者便参考了两本关于 Reactive Java 编程方面的书:《Reactive Java Programming》和《Reactive Programming with RxJava》。遗憾的是,两者尽管详细地描述 RxJava 的使用方法,然而却没有把 Reactive 使用场景讨论到要点上,如《Reactive Programming with RxJava》所给出的使用场景说明:
When You Need Reactive Programming
Reactive programming is useful in scenarios such as the following:
- Processing user events such as mouse movement and clicks, keyboard typing,GPS signals changing over time as users move with their device, device gyroscope signals, touch events, and so on.
- Responding to and processing any and all latency-bound IO events from disk or network, given that IO is inherently asynchronous …
- Handling events or data pushed at an application by a producer it cannot control …
实际上,以上三种使用场景早已在 Java 生态中完全地实现并充分地实践,它们对应的技术分别是 Java AWT/Swing、NIO/AIO 以及 JMS(Java 消息服务)。那么,再谈 RxJava 的价值又在哪里呢?如果读者是初学者,或许还能蒙混过关。好奇心促使笔者重新开始踏上探索 Reactive 之旅。
理解 Reactive
2017年 Java 技术生态中,最有影响力的发布莫过于 Java 9 和 Spring 5,前者主要支持模块化,次要地提供了 Flow API 的支持,后者则将”身家性命“压在 Reactive 上面,认为 Reactive 是未来的趋势,它以 Reactive 框架 Reactor 为基础,逐步构建一套完整的 Reactive 技术栈,其中以 WebFlux 技术为最引人关注,作为替代 Servlet Web 技术栈的核心特性,承载了多年 Spring 逆转 Java EE 的初心。于是,业界开始大力地推广 Reactive 技术,于是笔者又接触到一些关于 Reactive 的讲法。
关于 Reactive 的一些讲法
其中笔者挑选了以下三种出镜率最高的讲法:
- Reactive 是异步非阻塞编程
- Reactive 能够提升程序性能
- Reactive 解决传统编程模型遇到的困境
第一种说法描述了功能特性,第二种说法表达了性能收效,第三种说法说明了终极目地。下面的讨论将围绕着这三种讲法而展开,深入地探讨 Reactive Programming 的实质,并且理解为什么说 Reactive Programming 是”一种技术,各自表述“。
同时,讨论的方式也一反常态,并不会直奔主题地解释什么 Reactive Programming,而是从问题的角度出发,从 Reactive 规范和框架的论点,了解传统编程模型中所遇到的困境,逐步地揭开 Reactive 神秘的面纱。其中 Reactive 规范是 JVM Reactive 扩展规范 Reactive Streams JVM,而 Reactive 实现框架则是最典型的实现:
- Java 9 Flow API
- RxJava
- Reactor
传统编程模型中的某些困境
Reactor 认为阻塞可能是浪费的
3.1. Blocking Can Be Wasteful
Modern applications can reach huge numbers of concurrent users, and, even though the capabilities of modern hardware have continued to improve, performance of modern software is still a key concern.
There are broadly two ways one can improve a program’s performance:
- parallelize: use more threads and more hardware resources.
- seek more efficiency in how current resources are used.
Usually, Java developers write programs using blocking code. This practice is fine until there is a performance bottleneck, at which point the time comes to introduce additional threads, running similar blocking code. But this scaling in resource utilization can quickly introduce contention and concurrency problems.
Worse still, blocking wastes resources.
So the parallelization approach is not a silver bullet.
将以上 Reactor 观点归纳如下,它认为:
- 阻塞导致性能瓶颈和浪费资源
- 增加线程可能会引起资源竞争和并发问题
- 并行的方式不是银弹(不能解决所有问题)
第三点基本上是废话,前面两点则较为容易理解,为了减少理解的偏差,以下讨论将结合示例说明。
理解阻塞的弊端
假设有一个数据加载器,分别加载配置、用户信息以及订单信息,如下图所示:
- 图示
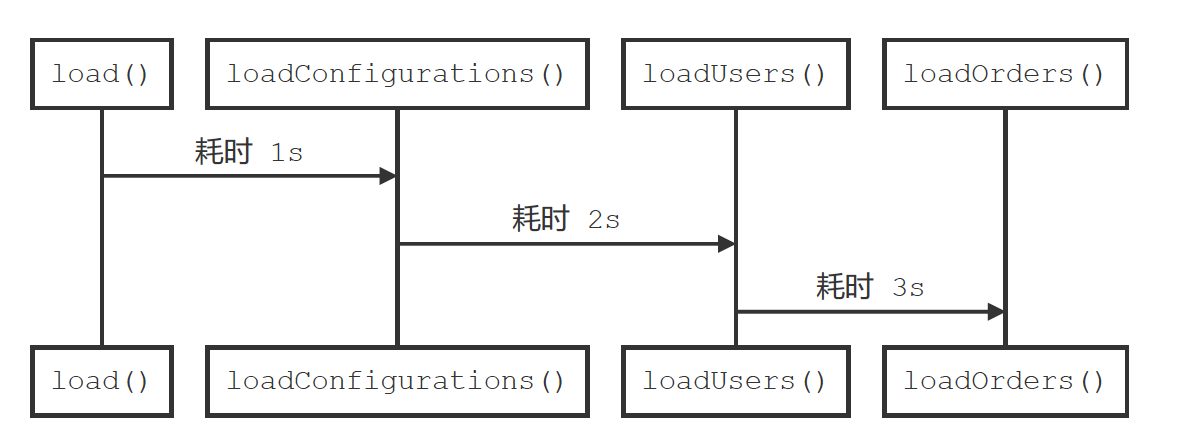
- Java 实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
public class DataLoader {
public final void load() {
long startTime = System.currentTimeMillis(); // 开始时间
doLoad(); // 具体执行
long costTime = System.currentTimeMillis() - startTime; // 消耗时间
System.out.println("load() 总耗时:" + costTime + " 毫秒");
}
protected void doLoad() { // 串行计算
loadConfigurations(); // 耗时 1s
loadUsers(); // 耗时 2s
loadOrders(); // 耗时 3s
} // 总耗时 1s + 2s + 3s = 6s
protected final void loadConfigurations() {
loadMock("loadConfigurations()", 1);
}
protected final void loadUsers() {
loadMock("loadUsers()", 2);
}
protected final void loadOrders() {
loadMock("loadOrders()", 3);
}
private void loadMock(String source, int seconds) {
try {
long startTime = System.currentTimeMillis();
long milliseconds = TimeUnit.SECONDS.toMillis(seconds);
Thread.sleep(milliseconds);
long costTime = System.currentTimeMillis() - startTime;
System.out.printf("[线程 : %s] %s 耗时 : %d 毫秒\n",
Thread.currentThread().getName(), source, costTime);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) {
new DataLoader().load();
}
}
- 运行结果
1
2
3
4
[线程 : main] loadConfigurations() 耗时 : 1005 毫秒
[线程 : main] loadUsers() 耗时 : 2002 毫秒
[线程 : main] loadOrders() 耗时 : 3001 毫秒
load() 总耗时:6031 毫秒
- 结论
由于加载过程串行执行的关系,导致消耗实现线性累加。Blocking 模式即串行执行 。
不过 Reactor 也提到,以上问题可通过并行的方式来解决,不过编写并行程序较为复杂,那么其中难点在何处呢?
理解并行的复杂
再将以上示例由串行调整为并行,如下图所示:
- 图示
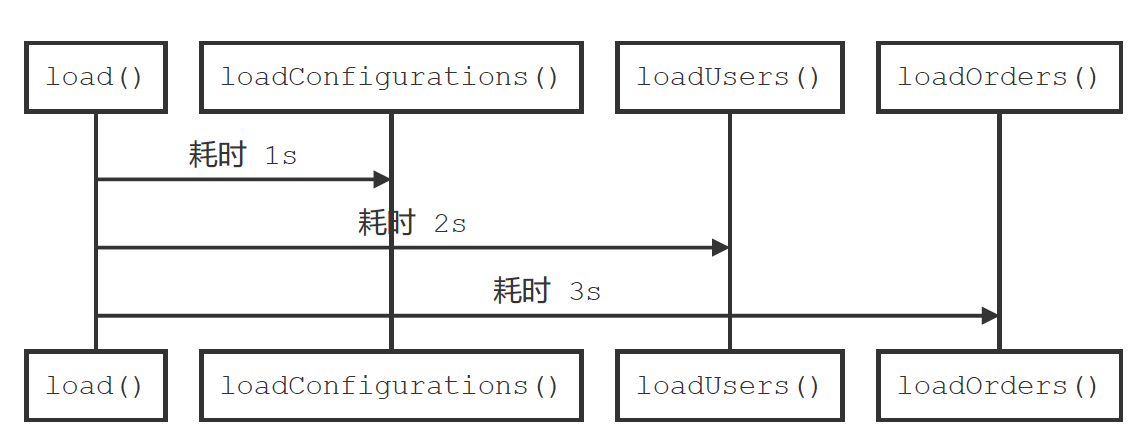
- Java 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class ParallelDataLoader extends DataLoader {
protected void doLoad() { // 并行计算
ExecutorService executorService = Executors.newFixedThreadPool(3); // 创建线程池
CompletionService completionService = new ExecutorCompletionService(executorService);
completionService.submit(super::loadConfigurations, null); // 耗时 >= 1s
completionService.submit(super::loadUsers, null); // 耗时 >= 2s
completionService.submit(super::loadOrders, null); // 耗时 >= 3s
int count = 0;
while (count < 3) { // 等待三个任务完成
if (completionService.poll() != null) {
count++;
}
}
executorService.shutdown();
} // 总耗时 max(1s, 2s, 3s) >= 3s
public static void main(String[] args) {
new ParallelDataLoader().load();
}
}
- 运行结果
1
2
3
4
[线程 : pool-1-thread-1] loadConfigurations() 耗时 : 1003 毫秒
[线程 : pool-1-thread-2] loadUsers() 耗时 : 2005 毫秒
[线程 : pool-1-thread-3] loadOrders() 耗时 : 3005 毫秒
load() 总耗时:3068 毫秒
- 结论
明显地,程序改造为并行加载后,性能和资源利用率得到提升,消耗时间取最大者,即三秒,由于线程池操作的消耗,整体时间将略增一点。不过,以上实现为什么不直接使用 Future#get() 方法强制所有任务执行完毕,然后再统计总耗时?
Reactor 这方面的看法并没有向读者清晰地表达全秒,不过这还不是全部,听听它接下来的说法。
Reactor 认为异步不一定能够救赎
3.2. Asynchronicity to the Rescue?
The second approach (mentioned earlier), seeking more efficiency, can be a solution to the resource wasting problem. By writing asynchronous, non-blocking code, you let the execution switch to another active task using the same underlying resources and later come back to the current process when the asynchronous processing has finished.
Java offers two models of asynchronous programming:
- Callbacks: Asynchronous methods do not have a return value but take an extra
callbackparameter (a lambda or anonymous class) that gets called when the result is available. A well known example is Swing’sEventListenerhierarchy.- Futures: Asynchronous methods return a
Future<T>immediately. The asynchronous process computes aTvalue, but theFutureobject wraps access to it. The value is not immediately available, and the object can be polled until the value is available. For instance,ExecutorServicerunningCallable<T>tasks useFutureobjects.Are these techniques good enough? Not for every use case, and both approaches have limitations.
Callbacks are hard to compose together, quickly leading to code that is difficult to read and maintain (known as “Callback Hell”).
Futures are a bit better than callbacks, but they still do not do well at composition, despite the improvements brought in Java 8 by
CompletableFuture.
再次将以上观点归纳,它认为:
- Callbacks 是解决非阻塞的方案,然而他们之间很难组合,并且快速地将代码引导至 “Callback Hell” 的不归路
- Futures 相对于 Callbacks 好一点,不过还是无法组合,不过
CompletableFuture能够提升这方面的不足
以上 Reactor 的观点仅给出了结论,没有解释现象,其中场景设定也不再简单直白,从某种程度上,这也侧面地说明,Reactive Programming 实际上是”高端玩家“的游戏。接下来,本文仍通过示例的方式,试图解释”Callback Hell” 问题以及 Future 的限制。
理解 “Callback Hell”
- Java GUI 示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
public class JavaGUI {
public static void main(String[] args) {
JFrame jFrame = new JFrame("GUI 示例");
jFrame.setBounds(500, 300, 400, 300);
LayoutManager layoutManager = new BorderLayout(400, 300);
jFrame.setLayout(layoutManager);
jFrame.addMouseListener(new MouseAdapter() { // callback 1
@Override
public void mouseClicked(MouseEvent e) {
System.out.printf("[线程 : %s] 鼠标点击,坐标(X : %d, Y : %d)\n",
currentThreadName(), e.getX(), e.getY());
}
});
jFrame.addWindowListener(new WindowAdapter() { // callback 2
@Override
public void windowClosing(WindowEvent e) {
System.out.printf("[线程 : %s] 清除 jFrame... \n", currentThreadName());
jFrame.dispose(); // 清除 jFrame
}
@Override
public void windowClosed(WindowEvent e) {
System.out.printf("[线程 : %s] 退出程序... \n", currentThreadName());
System.exit(0); // 退出程序
}
});
System.out.println("当前线程:" + currentThreadName());
jFrame.setVisible(true);
}
private static String currentThreadName() { // 当前线程名称
return Thread.currentThread().getName();
}
}
- 运行结果
点击窗体并关闭窗口,控制台输出如下:
1
2
3
4
5
6
7
8
9
当前线程:main
[线程 : AWT-EventQueue-0] 鼠标点击,坐标(X : 180, Y : 121)
[线程 : AWT-EventQueue-0] 鼠标点击,坐标(X : 180, Y : 122)
[线程 : AWT-EventQueue-0] 鼠标点击,坐标(X : 180, Y : 122)
[线程 : AWT-EventQueue-0] 鼠标点击,坐标(X : 180, Y : 122)
[线程 : AWT-EventQueue-0] 鼠标点击,坐标(X : 180, Y : 122)
[线程 : AWT-EventQueue-0] 鼠标点击,坐标(X : 201, Y : 102)
[线程 : AWT-EventQueue-0] 清除 jFrame...
[线程 : AWT-EventQueue-0] 退出程序...
- 结论
Java GUI 以及事件/监听模式基本采用匿名内置类实现,即回调实现。从本例可以得出,鼠标的点击确实没有被其他线程给阻塞。不过当监听的维度增多时,Callback 实现也随之增多。Java Swing 事件/监听是一种典型的既符合异步非阻塞,又属于 Callback 实现的场景,其并发模型可为同步或异步。不过,在 Java 8 之前,由于接口无法支持 default 方法,当接口方法过多时,通常采用 Adapter 模式作为缓冲方案,达到按需实现的目的。尤其在 Java GUI 场景中。即使将应用的 Java 版本升级到 8 ,由于这些 Adapter ”遗老遗少“实现的存在,使得开发人员仍不得不面对大量而繁琐的 Callback 折中方案。既然 Reactor 提出了这个问题,那么它或者 Reactive 能否解决这个问题呢?暂时存疑,下一步是如何理解 Future 的限制。
理解 Future 的限制
Reactor 的观点仅罗列 Future 的一些限制,并没有将它们解释清楚,接下来用两个例子来说明其中原委。
限制一:Future 的阻塞性
在前文示例中,ParallelDataLoader 利用 CompletionService API 实现 load*() 方法的并行加载,如果将其调整为 Future 的实现,可能的实现如下:
- Java
Future阻塞式加载示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public class FutureBlockingDataLoader extends DataLoader {
protected void doLoad() {
ExecutorService executorService = Executors.newFixedThreadPool(3); // 创建线程池
runCompletely(executorService.submit(super::loadConfigurations)); // 耗时 >= 1s
runCompletely(executorService.submit(super::loadUsers)); // 耗时 >= 2s
runCompletely(executorService.submit(super::loadOrders)); // 耗时 >= 3s
executorService.shutdown();
} // 总耗时 sum(>= 1s, >= 2s, >= 3s) >= 6s
private void runCompletely(Future<?> future) {
try {
future.get(); // 阻塞等待结果执行
} catch (Exception e) {
}
}
public static void main(String[] args) {
new FutureBlockingDataLoader().load();
}
}
- 运行结果
1
2
3
4
[线程 : pool-1-thread-1] loadConfigurations() 耗时 : 1003 毫秒
[线程 : pool-1-thread-2] loadUsers() 耗时 : 2004 毫秒
[线程 : pool-1-thread-3] loadOrders() 耗时 : 3002 毫秒
load() 总耗时:6100 毫秒
- 结论
ParallelDataLoader 加载耗时为”3068 毫秒“,调整后的 FutureBlockingDataLoader 则比串行的 DataLoader 加载耗时(“6031 毫秒”)还要长。说明Future#get() 方法不得不等待任务执行完成,换言之,如果多个任务提交后,返回的多个 Future 逐一调用 get() 方法时,将会依次 blocking,任务的执行从并行变为串行。这也是之前为什么 ParallelDataLoader 不采取 Future 的解决方案的原因。
限制二:Future 不支持链式操作
由于 Future 无法实现异步执行结果链式处理,尽管 FutureBlockingDataLoader 能够解决方法数据依赖以及顺序执行的问题,不过它将并行执行带回了阻塞(串行)执行。所以,它不是一个理想实现。不过 CompletableFuture 可以帮助提升 Future 的限制:
- Java
CompletableFuture重构Future链式实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class FutureChainDataLoader extends DataLoader {
protected void doLoad() {
CompletableFuture
.runAsync(super::loadConfigurations)
.thenRun(super::loadUsers)
.thenRun(super::loadOrders)
.whenComplete((result, throwable) -> { // 完成时回调
System.out.println("加载完成");
})
.join(); // 等待完成
}
public static void main(String[] args) {
new ChainDataLoader().load();
}
}
- 运行结果
1
2
3
4
5
[线程 : ForkJoinPool.commonPool-worker-1] loadConfigurations() 耗时 : 1000 毫秒
[线程 : ForkJoinPool.commonPool-worker-1] loadUsers() 耗时 : 2005 毫秒
[线程 : ForkJoinPool.commonPool-worker-1] loadOrders() 耗时 : 3001 毫秒
加载完成
load() 总耗时:6093 毫秒
- 结论
通过输出日志分析, FutureChainDataLoader 并没有像 FutureBlockingDataLoader 那样使用三个线程分别执行加载任务,仅使用了一个线程,换言之,这三次加载同一线程完成,并且异步于 main 线程,如下所示:
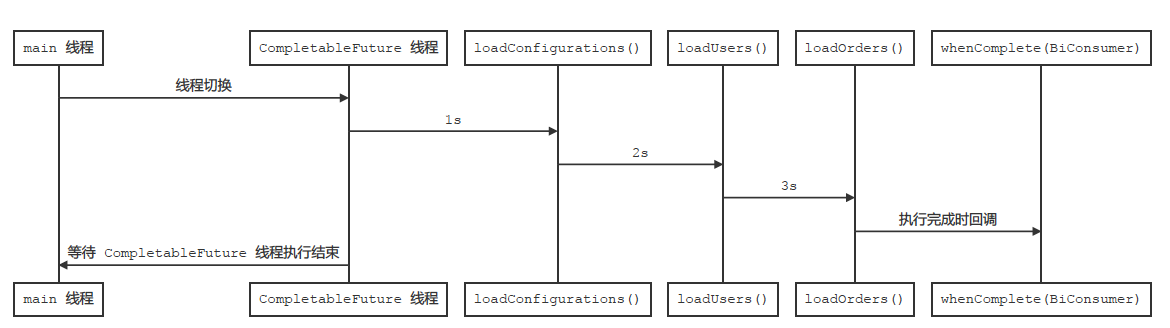
尽管 CompletableFuture 不仅是异步非阻塞操作,而且还能将 Callback 组合执行,也不存在所谓的 ”Callback Hell“ 等问题。如果强制等待结束的话,又回到了阻塞编程的方式。同时,相对于 FutureBlockingDataLoader 实现,重构后的 FutureChainDataLoader 不存在明显性能提升。
稍作解释,
CompletableFuture不仅可以支持Future链式操作,而且提供三种生命周期回调,即执行回调(Action)、完成时回调(Complete)、和异常回调(Exception),类似于 Spring 4ListenableFuture以及 GuavaListenableFuture。
至此,Reactor 的官方参考文档再没有出现其他有关”传统编程模型中的某些困境“的描述,或许读者老爷和我一样,对 Reactive 充满疑惑,它真能解决以上问题吗?当然,监听则明,偏听则暗,下面我们再来参考 Reactive Streams JVM 的观点。
Reactive Streams JVM 认为异步系统和资源消费需要特殊处理
Handling streams of data—especially “live” data whose volume is not predetermined—requires special care in an asynchronous system. The most prominent issue is that resource consumption needs to be carefully controlled such that a fast data source does not overwhelm the stream destination. Asynchrony is needed in order to enable the parallel use of computing resources, on collaborating network hosts or multiple CPU cores within a single machine.
观点归纳:
- 流式数据容量难以预判
- 异步编程复杂
- 数据源和消费端之间资源消费难以平衡
此观点与 Reactor 相同的部分是,两者均认为异步编程复杂,而前者还提出了数据结构(流式数据)以及数据消费问题。
无论两者的观点孰优谁劣,至少说明一个现象,业界对于 Reactive 所解决的问题并非达到一致,几乎各说各话。那么,到底怎样才算 Reactive Programming 呢?
什么是 Reactive Programming
关于什么是 Reactive Programming,下面给出六种渠道的定义,尝试从不同的角度,了解 Reactive Programming 的意涵。首先了解的是 “The Reactive Manifesto” 中的定义
The Reactive Manifesto 中的定义
Reactive Systems are: Responsive, Resilient, Elastic and Message Driven.
https://www.reactivemanifesto.org/
该组织对 Reactive 的定义非常简单,其特点体现在以下关键字:
- 响应的(Responsive)
- 适应性强的(Resilient)
- 弹性的(Elastic)
- 消息驱动的(Message Driven)
不过这样的定义侧重于 Reactive 系统,或者说是设计 Reactive 系统的原则。
维基百科中的定义
维基百科作为全世界的权威知识库,其定义的公允性能够得到保证:
Reactive programming is a declarative programming paradigm concerned with data streams and the propagation of change. With this paradigm it is possible to express static (e.g. arrays) or dynamic (e.g. event emitters) data streams with ease, and also communicate that an inferred dependency within the associated execution model exists, which facilitates the automatic propagation of the changed data flow.
参考地址:https://en.wikipedia.org/wiki/Reactive_programming
维基百科认为 Reactive programming 是一种声明式的编程范式,其核心要素是数据流(data streams )与其传播变化( propagation of change),前者是关于数据结构的描述,包括静态的数组(arrays)和动态的事件发射器(event emitters)。由此描述,在笔者脑海中浮现出以下技术视图:
- 数据流:Java 8
Stream - 传播变化:Java
Observable/Observer - 事件/监听:Java
EventObject/EventListener
这些技术能够很好地满足维基百科对于 Reactive 的定义,那么, Reactive 框架和规范的存在意义又在何方?或许以上定义过于抽象,还无法诠释 Reactive 的全貌。于是乎,笔者想到了去 Spring 官方找寻答案,正如所愿,在 Spring Framework 5 官方参考文档中找到其中定义。
Spring 5 中的定义
The term “reactive” refers to programming models that are built around reacting to change — network component reacting to I/O events, UI controller reacting to mouse events, etc. In that sense non-blocking is reactive because instead of being blocked we are now in the mode of reacting to notifications as operations complete or data becomes available.
参考地址:https://docs.spring.io/spring/docs/current/spring-framework-reference/web-reactive.html#webflux-why-reactive
相对于维基百科的定义,Spring 5 WebFlux 章节同样也提到了变化响应(reacting to change ) ,并且还说明非阻塞(non-blocking)就是 Reactive。同时,其定义的侧重点在响应通知方面,包括操作完成(operations complete)和数据可用(data becomes available)。Spring WebFlux 作为 Reactive Web 框架,天然支持非阻塞,不过早在 Servlet 3.1 规范时代皆以实现以上需求,其中包括 Servlet 3.1 非阻塞 API ReadListener 和WriteListener,以及 Servlet 3.0 所提供的异步上下文 AsyncContext 和事件监听 AsyncListener。这些 Servlet 特性正是为 Spring WebFlux 提供适配的以及,所以 Spring WebFlux 能完全兼容 Servlet 3.1 容器。笔者不禁要怀疑,难道 Reactive 仅是新包装的概念吗?或许就此下结论还为时尚早,不妨在了解一下 ReactiveX 的定义。
ReactiveX 中的定义
广泛使用的 RxJava 作为 ReactiveX 的 Java 实现,对于 Reactive 的定义,ReactiveX 具备相当的权威性:
ReactiveX extends the observer pattern to support sequences of data and/or events and adds operators that allow you to compose sequences together declaratively while abstracting away concerns about things like low-level threading, synchronization, thread-safety, concurrent data structures, and non-blocking I/O.
参考地址:http://reactivex.io/intro.html
不过,ReactiveX 并没有直接给 Reactive 下定义,而是通过技术实现手段说明如何实现 Reactive。ReactiveX 作为观察者模式的扩展,通过操作符(Opeators)对数据/事件序列(Sequences of data and/or events )进行操作,并且屏蔽并发细节(abstracting away…),如线程 API(Exectuor 、Future、Runnable)、同步、线程安全、并发数据结构以及非阻塞 I/O。该定义的侧重点主要关注于实现,包括设计模式、数据结构、数据操作以及并发模型。除设计模式之外,Java 8 Stream API 具备不少的操作符,包括迭代操作 for-each、map/reduce 以及集合操作 Collector等,同时,通过 parallel() 和 sequential() 方法实现并行和串行操作间的切换,同样屏蔽并发的细节。至于数据结构,Stream 和数据流或集合序列可以画上等号。唯独在设计模式上,Stream 是迭代器(Iterator)模式实现,而 ReactiveX 则属于观察者(Observer)模式的实现。 对此,Reactor 做了进一步地解释。
Reactor 中的定义
The reactive programming paradigm is often presented in object-oriented languages as an extension of the Observer design pattern. One can also compare the main reactive streams pattern with the familiar Iterator design pattern, as there is a duality to the Iterable-Iterator pair in all of these libraries. One major difference is that, while an Iterator is pull-based, reactive streams are push-based.
http://projectreactor.io/docs/core/release/reference/#intro-reactive
同样地,Reactor 也提到了观察者模式(Observer pattern )和迭代器模式(Iterator pattern)。不过它将 Reactive 定义为响应流模式(Reactive streams pattern ),并解释了该模式和迭代器模式在数据读取上的差异,即前者属于推模式(push-based),后者属于拉模式(pull-based)。难道就因为这因素,就要使用 Reactive 吗?这或许有些牵强。个人认为,以上组织均没有坦诚或者简单地向用户表达,都采用一种模糊的描述,多少难免让人觉得故弄玄虚。幸运地是,我从 ReactiveX 官方找到一位前端牛人 André Staltz,他在学习 Reactive 过程中与笔者一样,吃了不少的苦头,在他博文《The introduction to Reactive Programming you’ve been missing》中,他给出了中肯的解释。
André Staltz 给出的定义
Reactive programming is programming with asynchronous data streams.
In a way, this isn’t anything new. Event buses or your typical click events are really an asynchronous event stream, on which you can observe and do some side effects. Reactive is that idea on steroids. You are able to create data streams of anything, not just from click and hover events. Streams are cheap and ubiquitous, anything can be a stream: variables, user inputs, properties, caches, data structures, etc.
他在文章指出,Reactive Programming 并不是新东西,而是司空见惯的混合物,比如事件总监、鼠标点击事件等。同时,文中也提到异步(asynchronous )以及数据流(data streams)等关键字。如果说因为 Java 8 Stream 是迭代器模式的缘故,它不属于Reactive Programming 范式的话,那么,Java GUI 事件/监听则就是 Reactive。那么,Java 开发人员学习 RxJava、Reactor、或者 Java 9 Flow API 的必要性又在哪里呢?因此,非常有必要深入探讨 Reactive Programming 的使用场景。
Reactive Programming 使用场景
正如同 Reactive Programming 的定义那样,各个组织各执一词,下面仍采用多方引证的方式,寻求 Reactive Programming 使用场景的“最大公约数”。
Reactive Streams JVM 认为的使用场景
The main goal of Reactive Streams is to govern the exchange of stream data across an asynchronous boundary.
https://github.com/reactive-streams/reactive-streams-jvm
Reactive Streams JVM 认为 Reactive Streams 用于在异步边界(asynchronous boundary)管理流式数据交换( govern the exchange of stream data)。异步说明其并发模型,流式数据则体现数据结构,管理则强调它们的它们之间的协调。
Spring 5 认为的使用场景
Reactive and non-blocking generally do not make applications run faster. They can, in some cases, for example if using the
WebClientto execute remote calls in parallel. On the whole it requires more work to do things the non-blocking way and that can increase slightly the required processing time.The key expected benefit of reactive and non-blocking is the ability to scale with a small, fixed number of threads and less memory. That makes applications more resilient under load because they scale in a more predictable way.
Spring 认为 Reactive 和非阻塞通常并非让应用运行更快速(generally do not make applications run faster),甚至会增加少量的处理时间,因此,它的使用场景则利用较少的资源,提升应用的伸缩性(scale with a small, fixed number of threads and less memory)。
ReactiveX 认为的使用场景
The ReactiveX Observable model allows you to treat streams of asynchronous events with the same sort of simple, composable operations that you use for collections of data items like arrays. It frees you from tangled webs of callbacks, and thereby makes your code more readable and less prone to bugs.
ReactiveX 所描述的使用场景与 Spring 的不同,它没有从性能入手,而是代码可读性和减少 Bugs 的角度出发,解释了 Reactive Programming 的价值。同时,强调其框架的核心特性:异步(asynchronous)、同顺序(same sort)和组合操作(composable operations)。它也间接地说明了,Java 8 Stream 在组合操作的限制,以及操作符的不足。
Reactor 认为的使用场景
Composability and readability
Data as a flow manipulated with a rich vocabulary of operators
Nothing happens until you subscribe
Backpressure or the ability for the consumer to signal the producer that the rate of emission is too high
High level but high value abstraction that is concurrency-agnostic
Reactor 同样强调结构性和可读性(Composability and readability)和高层次并发抽象(High level abstraction),并明确地表示它提供丰富的数据操作符( rich vocabulary of operators)弥补 Stream API 的短板,还支持背压(Backpressure)操作,提供数据生产者和消费者的消息机制,协调它们之间的产销失衡的情况。同时,Reactor 采用订阅式数据消费(Nothing happens until you subscribe)的机制,实现 Stream 所不具备的数据推送机制。
至此,讨论接近尾声,最后的部分将 Reactive Programming 内容加以总结。
总结 Reactive Programming
Reactive Programming 作为观察者模式(Observer) 的延伸,不同于传统的命令编程方式( Imperative programming)同步拉取数据的方式,如迭代器模式(Iterator) 。而是采用数据发布者同步或异步地推送到数据流(Data Streams)的方案。当该数据流(Data Steams)订阅者监听到传播变化时,立即作出响应动作。在实现层面上,Reactive Programming 可结合函数式编程简化面向对象语言语法的臃肿性,屏蔽并发实现的复杂细节,提供数据流的有序操作,从而达到提升代码的可读性,以及减少 Bugs 出现的目的。同时,Reactive Programming 结合背压(Backpressure)的技术解决发布端生成数据的速率高于订阅端消费的问题。
后记
2005年,李敖大师曾在上海复旦大学做过一次演讲,他在讲到“放弃自由主义,注重务实”的部分时,引述一段故事:
美国有一个报纸,办报的人叫ABBOTT,他晚年的时候写回忆录,他爸爸是一个写儿童书的作家,他爸爸临死前告诉他说,感觉到人间所有的教会的争执90%都是名词之争。这个小ABBOTT老了以后,他回忆这段话,他说我回忆我爸爸告诉我所有人间宗教的争执90%都是名词之争,他说我发现我爸爸数学不好,原来最后那10%也是名词之争。
实际上,名词之争的战场不限于宗教教会,技术领域不也是如此吗?Reactive Programming 实际是一种技术,却被各自表达。有些定义含糊不清,有些定义则空洞无实,还有一些则是夸大其词,只有少数保持客观中立。不免让然唏嘘技术领域的非理性营销。当了解了 Reactive Programming 的本质后,您的热情还能像如初般地高涨吗?